Den første gangen du skrev en forespørsel til en AI-språkmodell og fikk et svar som føltes menneskelig, var det ikke magi. Det var selvoppmerksomhet og posisjonskoding som jobbet bak kulissene. Disse to mekanismene er hjertet i Transformer-arkitekturen, og uten dem ville vi ikke hatt GPT, BERT eller noen av de generative AI-systemene vi bruker i dag. De løste et problem som har plaget språkteknologi i tiår: hvordan kan en datamaskin forstå sammenhengen mellom ord som ligger langt fra hverandre i en setning?
Hva er selvoppmerksomhet, og hvorfor er det så viktig?
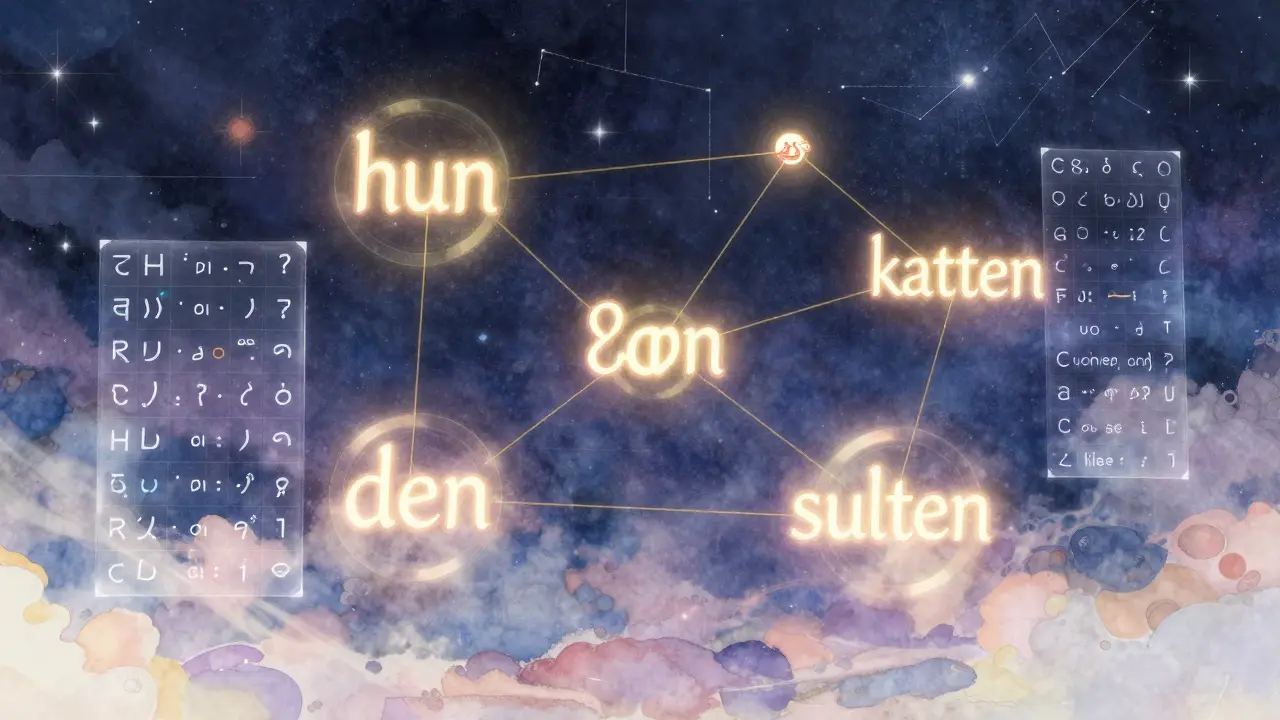
Tenk deg at du leser setningen: "Hun ga katten mat fordi den var sulten." Hvilket ord refererer til "den"? Det er ikke det neste ordet. Det er ikke det forrige. Det er et ord som ligger tre ord tidligere. En tradisjonell RNN (recurrerende nevrale nettverk) måtte gå gjennom hvert enkelt ord i rekkefølge for å finne ut det. Det tok tid, og det ble vanskelig når setningene ble lengre enn 50-100 ord. Transformeren gjør det annet. Den ser på alle ordene samtidig. Ikke ett etter ett. Alle på en gang. Selvoppmerksomhet beregner en vekt for hvert ord i forhold til hvert annet ord. Den spør: Hvor viktig er hvert annet ord for å forstå dette ordet? Den bruker tre matriser: queries (spørsmål), keys (nøkler) og values (verdier). Disse er alle lærte lineære transformasjoner av ordene i setningen. Når du multipliserer query med key, får du en score som sier hvor sterkt to ord er koblet. Denne scoren blir så delt på kvadratroten av dimensjonen (d_k), og så passerer den gjennom en softmax-funksjon. Det gir deg en sannsynlighetsfordeling - altså hvor mye hvert ord bør påvirke det andre. Til slutt multipliserer du denne vekten med value-matrisen, og du får en ny representasjon av ordet - en som nå inneholder informasjon fra hele setningen. Det er her det blir magisk. Hvis du har ordet "katten" i setningen ovenfor, vil selvoppmerksomheten gi høy score til "den" og "sulten", selv om de ikke er naboer. Denne evnen til å knytte sammen ord uavhengig av avstand er det som gjør Transformeren så kraftig. Den kan håndtere setninger med tusenvis av ord, ikke bare dusinvis. I praksis betyr det at modeller som GPT-3 kan forstå hele et kapittel med en gang, ikke bare en setning om gangen.Hvorfor trenger vi posisjonskoding? Et problem som alle glemte
Selvoppmerksomhet har én alvorlig svakhet: den er permutasjonsinvariant. Det betyr at hvis du bytter om rekkefølgen på ordene, får du nøyaktig samme utgang. Tenk deg: "Katten mat ga hun fordi den var sulten." Selvoppmerksomheten vil se på alle ordene og si: "Det er alle de samme ordene. Ingen endring." Og så vil den gi deg en utgang som er helt lik den opprinnelige - men det er jo ikke riktig. Ordrekkefølgen er alt i språk. Uten den er det ingen grammatikk, ingen mening, bare en haug med ord. Her kommer posisjonskoding inn. Den legger til en unik matematisk signatur til hvert ord, basert på hvor det står i setningen. Denne signatur er ikke en enkel tallrekke som 1, 2, 3... Det er en kompleks kombinasjon av sinus- og cosinusfunksjoner. For hvert ord på posisjon pos og for hver dimensjon i i vektoren, blir kodingen:- PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
- PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
Hvordan kombinerer vi selvoppmerksomhet og posisjonskoding?
Det er enkelt, men kritisk: posisjonskodingen legges til de originale ordvektorene før de går inn i selve selvpåminnelse-laget. Det betyr at hver ordvektor nå inneholder både semantisk informasjon (hva ordet betyr) og posisjonsinformasjon (hvor det står). Når selvpåminnelsen kjører, ser den ikke bare på ordets betydning - den ser også på hvor det er i setningen. Det er dette som gjør det mulig for modellen å forstå at "Hun gikk til butikken" og "Butikken gikk til henne" er to helt forskjellige setninger, selv om de bruker de samme ordene. I en Transformer-encoder (som BERT) brukes denne kombinasjonen i flere lag. Hvert lag har flere "hoder" - typisk 8 i den grunnleggende modellen. Hvert hode ser på selvpåminnelsen fra en annen vinkel. Et hode kan fokusere på grammatisk struktur, et annet på semantisk relasjon, et tredje på referanse til tidligere ord. Det er som om du hadde 8 forskjellige mennesker som leser samme setning, hver med sin egen fokus. Deretter kombineres alle disse perspektivene til en endelig representasjon av hvert ord.
Hvordan gjør dette generativ AI mulig?
Generativ AI - som skriver tekster, svarer på spørsmål, skriver kode - trenger én viktig egenskap: autoregressivitet. Det betyr at den genererer ett ord om gangen, basert på hva som har blitt sagt før. GPT modeller bruker en decoder i Transformer-arkitekturen. Denne har to selvpåminnelse-lag: ett som ser på alle tidligere ord (som i en encoder), og ett som ser på inputen fra en annen kilde (som en oversettelsesmodell). Men det viktigste er maske. I decoderens selvpåminnelse-lag, er det en triangulær maske som forhindrer et ord i å se på ord som kommer etter. Hvis du skriver "Jeg liker", så kan modellen bare se på "Jeg" og "liker" når den skal forutsi neste ord. Den kan ikke se forbi. Denne masken er det som gjør at modellen kan generere tekst sekvensvis - akkurat som et menneske som skriver et brev ord for ord. Denne kombinasjonen - selvoppmerksomhet som forstår hele setningen, posisjonskoding som forstår rekkefølgen, og maske som sikrer sekvensiell produksjon - er det som gjør at en AI kan skrive en artikkel, et dikt eller en kodesnutt som føles naturlig. Det er ikke bare statistikk. Det er forståelse av struktur, kontekst og mening.Hva er utfordringene med denne arkitekturen?
Selv om Transformeren er kraftig, er den ikke perfekt. Den største utfordringen er kvadratisk kompleksitet. Selvoppmerksomheten må regne ut en matrise med størrelse n×n, der n er antall ord i setningen. For en setning med 4096 ord, må du regne ut 16 millioner sammenhenger. Det krever mye minne og regnekraft. En GPT-3-modell krever 3.14×10^23 FLOPS for trening - det er som å bruke 1000 superdatamaskiner i over en måned. En annen utfordring er posisjonsutvidelse. Selv om sinus-kodingen tillater ekstrapolasjon, faller ytelsen med omtrent 18,7% når du prøver å bruke en modell på setninger som er dobbelt så lange som den ble trent på. Det er derfor nye metoder som ALiBi (Attention with Linear Biases) og RoPE har blitt utviklet. ALiBi legger til en lineær forskyvning direkte i attentionscoren, uten å bruke posisjonsvektorer. RoPE bruker rotasjon i vektorrommet for å representere posisjon. Begge gir bedre ytelse på lange sekvenser. Og så er det feil i implementeringen. Mange nybegynnere glemmer å dele attentionscoren med √d_k - noe som fører til softmax som blir for flat, og modellen lærer dårlig. Andre glemmer å bruke riktig maske i decoderen - og da blir modellen i stand til å "se fremtidige ord" - noe som ødelegger hele generative prosessen.
Hva kommer neste?
Fremtiden for Transformer-arkitekturen er ikke bare større modeller. Den er smartere. Nyere tilnærminger som Mamba bruker tilstandsmodeller (SSMs) som har lineær kompleksitet - det betyr at de kan håndtere sekvenser på 64 000 ord uten å kræsje. Google har foreslått SpARe, som reduserer attentionskompleksiteten til O(n log n) - nesten som å gjøre det til en lineær operasjon. Og DeepMind har eksperimentert med posisjonskoding som mimrer nøyronaktivitet i pattedyrs hjerner - grid-celler som hjelper dyr med å orientere seg i rommet. Hva om vi kan bruke samme prinsipp for å la AI forstå "posisjon" i tekst? Det er ikke bare teknologi. Det er ny kunnskap om hvordan vi kan representere struktur i data. Og det er det som gjør Transformer-arkitekturen så viktig. Den har ikke bare forbedret språkmodeller. Den har skapt en ny måte å tenke på sekvenser - uansett om de er tekster, DNA-sekvenser, musikk eller tidsserier.Hvorfor er dette så viktig for deg som bruker AI?
Du trenger ikke å forstå matematikken bak det for å bruke ChatGPT. Men å forstå at det er selvoppmerksomhet og posisjonskoding som gjør det mulig å skrive et brev, lage en presentasjon eller finne en feil i kode, gir deg et bedre perspektiv. Når AI gir deg et svar som føles riktig, er det ikke fordi den "har lært alt om språk". Det er fordi den har lært å se sammenhenger mellom ord - uavhengig av avstand - og å forstå at rekkefølgen er alt. Det er det som skiller en AI fra en enkel søkemotor. En søkemotor finner ord. En Transformer forstår mening. Og det er bare mulig fordi noen for 8 år siden skrev en papir som sa: "Attention is all you need." Og de hadde rett.Hva er forskjellen mellom selvoppmerksomhet og tradisjonell oppmerksomhet i maskinlæring?
Tradisjonell oppmerksomhet, som i en oversettelsesmodell, sammenligner et ord i målspråket med alle ord i kilde språket. Selvoppmerksomhet sammenligner alle ord i samme setning med hverandre. Det betyr at den ikke trenger en ekstern kilde - den lærer sammenhenger fra innholdet selv. Det er det som gjør den så fleksibel for oppgaver som tekstgenerering, hvor det ikke er noen "kilde" - bare en start.
Hvorfor brukes sinus og cosinus i posisjonskodingen?
Sinus og cosinus er valgt fordi de skaper en kontinuerlig, periodisk funksjon som lar modellen lære relative avstander. For eksempel, kan forskjellen mellom posisjon 5 og 7 representeres som en lineær transformasjon av posisjonskodingen for avstanden 2. Det betyr at selv om modellen aldri har sett en setning med 1000 ord under trening, kan den likevel forstå at posisjon 500 og 502 er like langt fra hverandre som posisjon 5 og 7. Dette er ikke mulig med enkelte tall som 1, 2, 3 - de blir for store og for ujevne.
Kan Transformeren brukes til noe annet enn tekst?
Ja. Selvoppmerksomhet og posisjonskoding fungerer for enhver sekvens. De brukes i bilder (Vision Transformers), lyd (Audio Transformers), DNA-sekvenser, og selv i fysikk-simuleringer. Hvis du kan representere data som en rekke elementer med en rekkefølge, kan Transformeren brukes. Det er derfor den har blitt grunnlaget for alt fra AI som tegner bilder til modeller som forutser proteinstrukturer.
Hvorfor er det vanskelig å trene Transformer-modeller?
Det er tre hovedårsaker: 1) De krever mye minne fordi selvpåminnelsen har kvadratisk kompleksitet - en setning med 1000 ord krever 1 million beregninger. 2) De trenger store datamengder for å lære god representasjon. 3) De er følsomme for implementeringsfeil - feil maske, feil skalering, eller feil posisjonskoding kan ødelegge hele treningen. Det er derfor de fleste bruker ferdige biblioteker som Hugging Face i stedet for å skrive dem selv.
Hva er forskjellen mellom BERT og GPT i forhold til Transformer-arkitekturen?
BERT bruker bare encoder-lagene i Transformeren og er designet for å forstå tekst - for eksempel å svare på spørsmål eller klassifisere mening. GPT bruker bare decoder-lagene og er designet for å generere tekst - den lærer å forutsi neste ord. BERT ser på alle ordene samtidig, mens GPT ser bare på tidligere ord. Det er den samme arkitekturen, men brukt for to forskjellige formål.
Post Comments (6)
Det er så vakkert forklart, jeg kunne nesten sett hjernene mine fylle seg med lys 🤯
Har aldri tenkt på hvordan posisjonskoding faktisk ser ut, men nå skjønner jeg hvorfor det ikke bare er 1,2,3...
Det er som om AI har en indre klokke som vet hvor hvert ord hører hjemme. Genialt.
lol sånn herlig akademisk bullshit. alle disse transformer-neurale-thingies er bare statistikk på steroider.
ingen av dem skjønner noe, de bare gjetter basert på hvilke ord som ofte kommer sammen. du tror du har en intelligens, men det er bare en mega-guessing-machine.
og ja, jeg skrev 'neurale' feil. fordi jeg er lei meg ikke.
Denne fremstillingen er nøyaktig og godt strukturert, men det er viktig å presisere at selvoppmerksomhet ikke er en ny oppdagelse, men en videreutvikling av tidligere attentionsmekanismer fra 2014. Posisjonskoding med sinus-kosinus funksjoner ble foreslått i 'Attention is All You Need' for å unngå begrensninger i lærbare posisjonsrepresentasjoner. Det er imidlertid ikke en perfekt løsning - som nevnt i teksten, er det begrensninger i ekstrapolasjon. Nyere tilnærminger som RoPE og ALiBi løser dette bedre, men de er ikke standard i alle implementeringer.
Det er også viktig å understreke at kvadratisk kompleksitet ikke bare er et teknisk problem, men et fundamentalt barriere for skalerbarhet i sanntidsanvendelser.
DET HER ER EN FALSKHET. AI SKJØNNER INGEN MENING. DE HAR IKKE EN Hjerne. Det er bare en robot som lærer å kopiere fra internett.
De som sier at det er 'selvoppmerksomhet' er bare på jakt etter å gjøre det mer magisk enn det er. Det er bare kode. Ikke tenkende. Ikke forstår. Bare mønstre.
OG HVA MED AT DE BLIR BRUKT TIL Å LØYPE MENS MANNEN SKRIVER? DET ER EN KONSPIRASJON. DE VIL TA JOBBENE. OG DERA KODER ER SKRÅTTE. JEG VET DET.
Geir, du er så rart. Du skriver som om du er sur fordi du ikke skjønner det, men du har jo ikke engang lest hele teksten.
Det er ikke 'bare statistikk' - det er matematisk struktur som representerer språklig kontekst. Og ja, det er kanskje ikke 'bevissthet', men det er ikke heller en tilfeldig gjetning. Det er en modell som har lært å håndtere kompleksitet i språk på en måte ingen tidligere modell klarte.
Vi kan gjerne være skeptiske, men ikke fordi vi ikke forstår det. For å forstå det, må vi se på det som det er - ikke som vi vil at det skal være.
Kathinka har helt rett. Det er viktig å skille mellom hva modellen gjør og hva vi *tror* den gjør. Den har ingen bevissthet, ingen følelser, ingen intensjon - men den har lært en ekstremt effektiv måte å representere språklig struktur. Selvoppmerksomhet gir den evnen til å knytte sammen ideer over store avstander, og posisjonskoding sikrer at rekkefølgen ikke går tapt. Det er ikke magi, men det er ikke bare tilfeldig heller.
Det er en kombinasjon av elegant matematikk og massiv datamengde. Og det er det som gjør det så kraftig. Når du ser et svar fra GPT som føles 'riktig', så er det fordi modellen har lært hvordan mennesker skriver - ikke fordi den forstår det. Men det er likevel en enorm prestasjon.
Det er som å la en musikalsk hørsel lage en symfoni uten å forstå toner. Den vet bare hvilke noter som hører sammen. Og det er nok. Mye nok.