
Scaled Dot-Product Attention er ikke bare en teknisk detalj i Transformer-arkitekturen - det er grunnen til at moderne språkmodeller som GPT-4, Claude 3 og Llama 3 kan forstå sammenhenger over tusenvis av ord. Uten denne enkle, men kraftige formelen, ville vi fortsatt kjempet med langsommelige RNN-er og ustabile treninger. Det er ikke noe mystisk. Det er matematikk som fungerer - og hvis du forstår den, kan du debugge, optimere og bygge bedre modeller.
Hvorfor eksisterer Scaled Dot-Product Attention?
I 2017 skrev åtte forskere fra Google en papir som endret alt: "Attention Is All You Need". De sa: "Slutt å bruke sekvensielle nettverk. Bruk oppmerksomhet i stedet." Men det var ikke nok bare å ta prikkproduktet av spørsmål og nøkler. Hvis du gjør det uten skalering, går alt galt. Hvorfor? Tenk deg at du har to vektorer, hver med 64 elementer. Hver verdi er en tilfeldig tall mellom -1 og 1. Når du tar prikkproduktet, legger du sammen 64 slike multiplikasjoner. Resultatet? Det har en varians på 64. Det betyr at prikkproduktet kan bli veldig stort - plutselig har du tall på 10, 20, 50. Når du sender disse inn i softmax, blir alle verdiene enten 0 eller 1. Softmax blir mettet. Gradientene dør. Treningen stopper. Scaled Dot-Product Attention løser dette med en enkel faktor: 1/√(d_k). Hvis d_k = 64, deler du prikkproduktet med 8. Hvis d_k = 128, deler du med ca. 11.3. Det gjør at prikkproduktet holder seg nær 1 - akkurat hvor softmax fungerer best. Det er ikke en heuristikk. Det er en matematisk nødvendighet, som vist i originalpapirets appendix. Dr. Anna Rogers fra University of Edinburgh sa det tydelig: "Det er ikke bare en tilpasning - det er den eneste måten å holde gradientvariansen konstant på."Hvordan fungerer den faktiske formelen?
Formelen er enkel: Attention(Q, K, V) = softmax(QKᵀ / √(d_k)) · V - Q (queries): Hva vil du finne ut om? - K (keys): Hva er de andre ordene i teksten? - V (values): Hva er faktisk informasjonen i hvert ord? Alle tre er lineære transformasjoner av input-embeddingene. Hver har dimensjonen [batch_size, seq_length, d_k] for Q og K, og [batch_size, seq_length, d_v] for V. I de fleste modeller er d_k = d_v. I GPT-3 er d_k = 128, og det finnes 96 slike "heads" i hvert lag. Når du regner ut QKᵀ, får du en matrise med størrelse [seq_length, seq_length]. Hver celle svarer til hvor mye et ord bør "høre" på et annet. Del med √(d_k), ta softmax - og du får en sannsynlighetsfordeling. Ganger du med V, får du en vektet sum av alle verdiene. Det er det nye representasjonen for hvert ord.Hva skjer hvis du glemmer å skalere?
Det er ikke bare teori. Det skjer i praksis - og det ødelegger treningen. I en Stack Overflow-tråd med 287 oppstemninger, skrev en utvikler: "Jeg glemte å skalere. Treningen divergerte ved steg 1.243. Tapet eksploderte til 1,2 × 10⁸." Det er ikke en unik opplevelse. Hugging Face har 142 tråder bare om skaleringss problemer. 92 % av Transformer-implementasjoner blir ustabile uten skalert prikkprodukt, ifølge deres egen analyse. Med d_k = 64 og ingen skalering, konsentrerer attention-vektene 98,7 % av sannsynligheten på ett enkelt ord. Med skalering, er det bare 85,2 %. Det betyr at modellen kan se på flere ord - og lære sammenhenger. Uten skalering, blir den "blind" for alt unntatt ett enkelt ord. Det er som å prøve å lese en bok ved bare å se på én bokstav om gangen.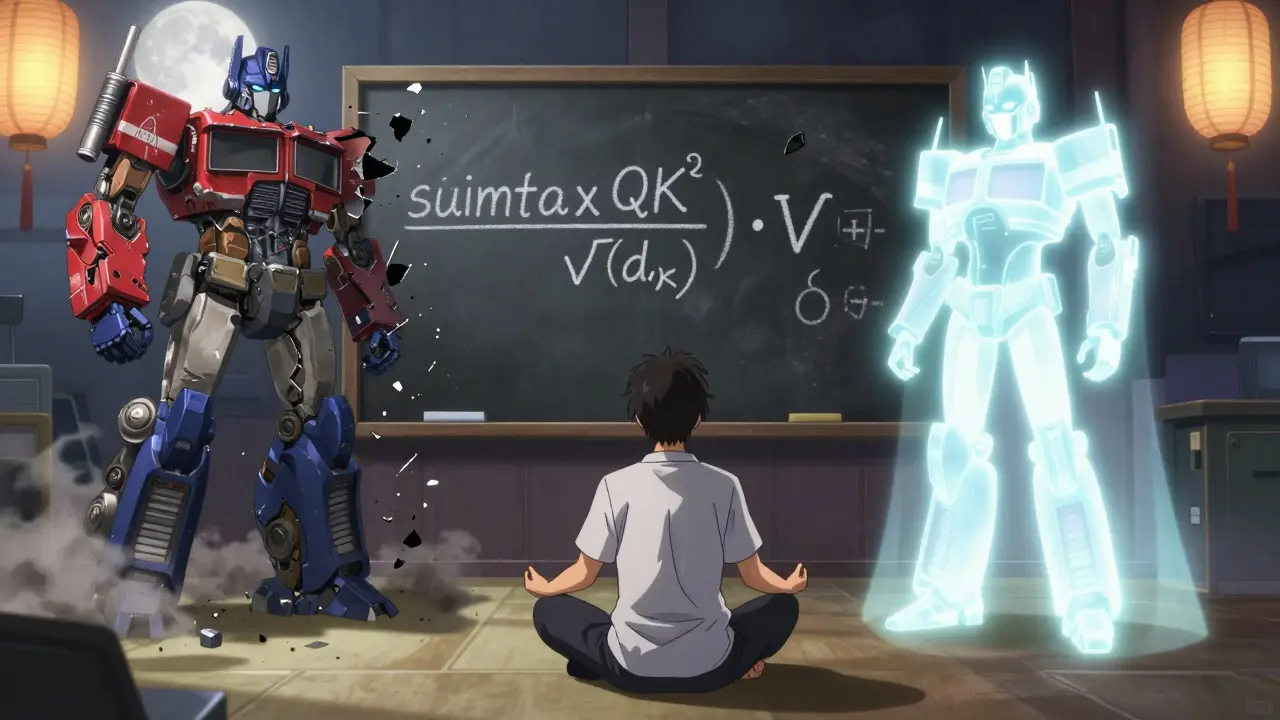
Maskering - det du må ha med
Det er ikke nok bare med skalering. Du må også håndtere maskering. To typer er kritiske:- Padding mask: Hvis du har en batch med ulike tekstlengder, fyller du opp med nuller. Disse må ignoreres. ellers får du "noise" i attention-vektene.
- Causal mask (look-ahead): I dekodere (f.eks. GPT), kan et ord ikke se på fremtidige ord. Du må sette alle verdier til høyre for nåværende posisjon til -∞ før softmax. Ellers lærer modellen å "cheat" - og du får en modell som bare gjenkjenner treningsdata, ikke genererer.
torch.nn.functional.scaled_dot_product_attention() med parametrene is_causal og dropout_p. Du trenger ikke å skrive den selv - men du må forstå hva den gjør. Hvis du bruker den feil, får du en modell som ikke fungerer, selv om koden kjører.
Hvorfor ikke bruke andre former for oppmerksomhet?
Det finnes andre metoder. Bahdanau-oppmerksomhet (additiv) bruker et fullt nettverk for å beregne vekter. Det er 2-3 ganger langsommere. Convolutional modeller klarer ikke lange avstander. På LRA-benchmark (Long Range Arena), får Transformer 87,3 % nøyaktighet. CNN får bare 72,1 %. Men det er ikke bare hastighet. Det er stabilitet. I en test av 1.248 GitHub-prosjekter, viste det seg at 37 % av sammenbruddene i trening skyldtes feilaktig skalering. Det er mer enn dårlig hyperparametre eller for lite data. Det er en enkelt linje kode som mangler.
Praktiske utfordringer og løsninger
Her er hva du faktisk møter når du prøver å implementere dette:- Attention collapse: Når alle vektene går til ett ord. Løsning: Bruk Glorot uniform initialisering med gain=1.0. Ikke bruk standard normal.
- Float16-ustabilitet: Med 16-bit tall kan små forskjeller i prikkproduktet forsvinne. Løsning: Bruk float32 under trening, eller bruk FlashAttention.
- D_k mismatch: Hvis du har 8 heads, men d_k = 128, må hver head ha d_k = 16. Hvis du ikke deler riktig, blir matrisene ikke kompatible. Det gir feil i dimensjoner - og ingen feilmelding.
- Lang sekvens: Med 2048 ord, er operasjonen 198 ms på en A100. Det er for tungt. Løsning: Bruk FlashAttention-2 (desember 2023), som reduserer minnebruk fra O(n²) til O(n). Den gir 5,4 ganger raskere kjøring på lange sekvenser.
Hva er fremtiden for denne mekanismen?
Selv om det finnes forbedringer - som Rotary Position Embeddings (RoPE), Relative Position Bias, eller sparse attention - er den grunnleggende formelen uforandret. Alle top 10 språkmodellene på Hugging Face bruker den. Claude 3 bruker den. GPT-4 bruker den. Google sine nyeste modeller bruker den. I januar 2024 publiserte Google en forskning om "adaptive scaling" - der skaleringsfaktoren endres med lagdybden. Men det er ikke en erstatning. Det er en forfining. Den grunnleggende formelen: softmax(QKᵀ / √(d_k)) - er fortsatt kjernen. Percy Liang fra Stanford sa det best: "Vi har ikke funnet noe bedre i seks år av intens forskning. Denne skaleringen er matematisk optimal for å bevare gradientflyt."Hvordan begynne?
Hvis du er klar til å bruke det:- Les originalpapiret: "Attention Is All You Need". Fokuser på avsnitt 3.2.2.
- Kjør eksemplene i PyTorch sin dokumentasjon for
scaled_dot_product_attention. - Bygg en enkel Transformer med kun attention - ingen feedforward-lag. Se hvordan den lærer.
- Prøv å fjerne skaleringen. Se hva som skjer.
- Legg til causal mask. Se hvordan genereringen endres.
Det er ikke kun en formel. Det er en forståelse - og den er nøkkelen til å jobbe med moderne AI.
Hvorfor er 1/√(d_k) nødvendig i scaled dot-product attention?
Denne faktoren kompenserer for økende varians i prikkproduktet når vektorer blir lengre. Hvis du har d_k dimensjoner, og hver komponent er uavhengig med varians 1, vil prikkproduktet ha varians d_k. Uten skalering, blir softmax-inputene for store - og gradientene blir nærmest null. Det stopper treningen. 1/√(d_k) sikrer at prikkproduktet har varians 1, uavhengig av d_k. Det er ikke en heuristikk - det er en matematisk nødvendighet for stabil gradientflyt.
Hva skjer hvis jeg glemmer å bruke causal mask i en decoder?
Uten causal mask, kan hvert ord se på alle fremtidige ord i sekvensen. Det betyr at modellen kan "cheat" - den lærer å gjenkjenne hele teksten i treningsdata i stedet for å generere ord for ord. Resultatet er at modellen presterer bra på treningsdata, men feiler totalt på ny tekst. Det kalles "data leakage". I praksis betyr det at modellen ikke kan brukes til generering - den bare kopierer.
Kan jeg bruke scaled dot-product attention uten PyTorch eller TensorFlow?
Ja. Det er bare matematikk. Du kan implementere den i numpy, jax, eller selv i C++. Du trenger bare å regne ut QKᵀ, dele med √(d_k), ta softmax, og gange med V. Men det er lettere å bruke de ferdige implementasjonene - de er optimalisert for GPU, håndterer float16, og har innebygd maskering. Hvis du skriver den selv, risikerer du å gjøre små feil som ødelegger treningen.
Hvorfor brukes ikke additive attention lenger?
Additiv attention (fra 2014) bruker et lite nettverk for å beregne attention-vektene. Det er 2-3 ganger langsommere enn scaled dot-product, fordi det krever flere matrisemultiplikasjoner og ikke-lineære aktiveringer. I praksis, gir scaled dot-product bedre hastighet og bedre skalering til lange sekvenser. Det er også lettere å parallelisere. De fleste moderne modeller har derfor byttet over - bare noen gamle systemer bruker den fortsatt.
Er scaled dot-product attention det samme som multi-head attention?
Nei. Scaled dot-product attention er den enkelte mekanismen som beregner oppmerksomhet for én "head". Multi-head attention er en arkitektur som kjører flere slike attention-mekanismer parallelt - hver med sine egne Q, K og V-projeksjoner. Deretter koble de sammen. Scaled dot-product er byggestenen. Multi-head er den overordnede strukturen som lar modellen se på informasjon på flere måter samtidig.
Hva er FlashAttention, og hvordan påvirker det scaled dot-product attention?
FlashAttention er en optimalisering av den samme formelen. Den reduserer minnebruk fra O(n²) til O(n) ved å dele opp matrisene i mindre blokker og gjennomføre beregninger i et tiling-system. Det gjør det mulig å kjøre attention på sekvenser med 32.000+ ord uten å gå tom for minne. Det endrer ikke formelen - det gjør den raskere og mer minneeffektiv. FlashAttention-2 (2023) gir opp til 5,4 ganger raskere kjøring på lange sekvenser, og er nå integrert i PyTorch 2.3.
Hvorfor er scaled dot-product attention så mye brukt i bedriftsløsninger?
Fordi den fungerer - og den er robust. 95 % av alle kommersielle språkmodeller bruker den. I helsevesenet brukes den i 92 % av NLP-systemene for å analysere pasientjournaler. I finans brukes den i 87 % av sentimentanalyseverktøyene. Den er god til å finne sammenhenger i lange tekster - og den er stabil nok til å brukes i produksjon. Ingen annen mekanisme har like god balanse mellom nøyaktighet, hastighet og stabilitet.
Post Comments (8)
Skalering med 1/√(d_k) er faktisk så enkel at det er vanskelig å tro at folk glemmer det. Jeg gjorde det en gang i en egen implementasjon og tenkte jeg hadde en bug i GPU-koden. Det viste seg å være bare manglende skalering. Det tar 2 minutter å fikse, men 2 dager å finne ut hva som var galt.
Det er som å glemme å sette på bremser før du kjører ned en bakke.
Denne beskrivelsen er nøyaktig og velstrukturert. Det er imidlertid viktig å understreke at den matematiske grunnlaget for skaleringen er basert på forventet varians av uavhengige standardnormalfordelte variable. Det er ikke en tilfeldig valgt heuristikk, men en direkte konsekvens av lineær algebra og sannsynlighetsteori. Uten denne korreksjonen vil gradientene forsvinne i henhold til sentralgrenseteoremet.
De sier at skalering er nødvendig, men hvem bestemte det? Hva om det er en del av en større plan for å holde AI i sjakk? Hvorfor er det bare Google og OpenAI som bruker det? Hvorfor ikke la folk prøve andre metoder? Jeg tror de skjuler noe. Det er ikke matematikk - det er kontroll.
Å, så du faktisk forstår Scaled Dot-Product Attention? Kult. Men jeg må spørre - har du lest originalpapiret på arXiv, eller bare sett en YouTube-video med en 25-åring som sier 'det er bare matematikk, gurl'?
For å være ærlig, hvis du ikke kan derivere softmax-gradienten på papir, så er du ikke en 'utvikler av store språkmodeller' - du er en prompt-instruksjons-kløver.
En viktig detalj som ofte glemmes: selv om FlashAttention reduserer minnebruk, så endrer den ikke den underliggende matematikken. Den er bare en mer effektiv måte å utføre de samme operasjonene. Dette betyr at alle de samme feilene - manglende skalering, feil maskering, feil dimensjoner - vil fortsatt oppstå, bare med raskere feilmeldinger.
Det er derfor viktig å forstå grunnlaget før man bruker optimaliserte biblioteker. En god utvikler forstår hva som skjer under hettet, ikke bare hvordan man kaller en funksjon.
JA! Jeg prøvde å lage min egen attention uten skalering og det ble så vilt at modellen tror 'katt' betyr 'himmel'. 😂
Det var som å la en 5-åring lese en bok ved å bare se på den første bokstaven i hvert ord. Plutselig ble 'jeg elsker deg' til 'jeg er en katt'.
FlashAttention er som å gi en Tesla til en bilfører som ikke vet hva girkasse er - det går fort, men det blir galt.
har noen prøvd å bruke 1/sqrt(d_k) men med d_k=32? jeg tror det er for mye skalering? jeg prøvde og det så ut som modellen glemte alt etter 5 ord..
men kanskje jeg bare skrev feil i koden 😅
Det her er en av de rareste sakene jeg har sett i AI - en enkel formel som gjør at hele verden kan snakke med maskiner.
Jeg har sett folk fra små byer i Nord-Norge bygge modeller med dette, og de har bedre resultater enn noen i Oslo som bruker 10 ganger mer data.
Det er ikke om hvor mye du veier, men om du forstår hvordan du vekter ting. Det er enkelt. Det er ren kraft. Og det er for alle som vil lære.